개인 추천 시스템, 랭킹 알고리즘의 중요성
20억 명이 넘는 사람들을 위한 개인화된 랭킹 시스템을 설계하는 것은 매우 중요한 만큼 구현하는 것이 매우 어렵습니다. 이 시스템을 사용해서 사용자들에게 알맞는 뉴스피드를 제공할 수 있기 때문에 이를 해결하는 것이 중요한 과제라고 볼 수 있습니다. 기계 학습이 없다면, 사람들의 뉴스피드는 지나치게 홍보적인 콘텐츠나 자주 게시하는 지인들의 콘텐츠 등, 관련이 없거나 흥미롭지 못한 콘텐츠로 넘쳐날 수 있습니다.
랭킹 알고리즘은 이러한 문제를 해결하는 데 도움이 되지만, 어떻게 하면 전 세계 수십억 명의 사람들과 개인적으로 관련이 있는 다양한 종류의 콘텐츠를 제공하는 시스템을 구축할 수 있을까요? 페이스북은 기계학습을 사용하여 사용자들에게 유익한 경험을 지원하기 위해 각 사람에게 가장 중요한 콘텐츠를 예측합니다. 의미 있는 상호 작용 및 품질 콘텐츠를 위한 모델은 신경망, 임베딩 및 오프라인 학습 시스템에 대한 다중 작업 학습과 같은 최첨단 머신러닝에 의해 작동됩니다.

랭킹 알고리즘의 간단한 이해
이 기능이 어떻게 작동하는지 이해하기 위해 가상의 사용자가 Facebook에 로그인하는 것부터 시작하겠습니다. A라는 사용자가 페이스북에 들어오면 새로운 피드, 게시물에 그의 친구의 사진과 또 다른 친구의 동영상이 올라와 있고, 그가 좋아하는 페이지와 그가 속한 그룹에도 새로운 영상과 사진들이 포스팅되어 있다고 합시다.
A가 이 콘텐츠의 제작자와 팔로우되어 있거나 좋아요를 눌렀기 때문에 관련도가 높을 것 입니다. 뉴스 피드에서 이러한 것들의 순위를 다른 것들보다 높게 매기려면, 우리는 A에게 가장 중요한 것과 가장 높은 가치가 있는 내용을 배울 필요가 있습니다. 예를 들어, A가 그의 친구와 많은 대화를 나누거나 사안비가 게시한 콘텐츠를 공유하는 경향이 있고, 실행 중인 비디오가 매우 최근의 것이라면, 후안이 이와 같은 콘텐츠를 좋아할 가능성이 높다고 볼 수 있습니다. 또한 A는 이전에 사진보다 비디오 컨텐츠에 더 많이 관여한 적이 있기 때문에 다른 친구의 사진 콘텐츠는 별로 관심이 없을 것 입니다. 이 경우, 우리의 랭킹 알고리즘은 A의 친구들 중 비디오 콘텐츠에 더 높은 순위를 매길 것 입니다.
하지만 자신의 선호도를 표현하는 유일한 방법이 콘텐츠 경험과 좋아요를 다는 것 뿐만이 아닙니다. 자신이 흥미롭게 여기는 기사를 공유하거나, 자신이 좋아하는 게임 스트리머의 비디오를 보거나, 친구들의 게시물에 댓글을 남길 수도 있습니다. 이럴 경우 알고리즘을 최적화해야 할 때 수학적으로 더 복잡해집니다. 좀 더 복잡하게 하기 위해서, 페이스북의 각 개인에 대해 우리가 평가해야 할 수천 개의 신호가 있고 이것들을 모두 고려해야 하기 때문에 최적화하기 위한 예측 모델 자체가 매우 복잡해지는 것 입니다.
추천 시스템, 랭킹 알고리즘의 구현
앞의 예시를 통해 대략적인 랭킹 알고리즘의 이론을 알았으므로, 이러한 최적화를 위한 시스템을 구축하는 방법을 결정해야 합니다. 20억 명 이상의 사람들이 이용할 수 있는 모든 게시물(사용자당 하루 평균 1,000개 이상의 게시물)에 점수를 매겨야 합니다. 그리고 더욱 중요한 점은 실시간으로 이 작업을 수행해야 합니다. 이를 위해 어떤 글이 몇 분 전에 게시되었더라도 많은 좋아요를 받았는지 알아야 합니다. 또한 A가 1분 전에 다른 콘텐츠들도 좋아했는지 알아야 하기 때문에 이 정보를 순위에 최적으로 활용할 수 있습니다.
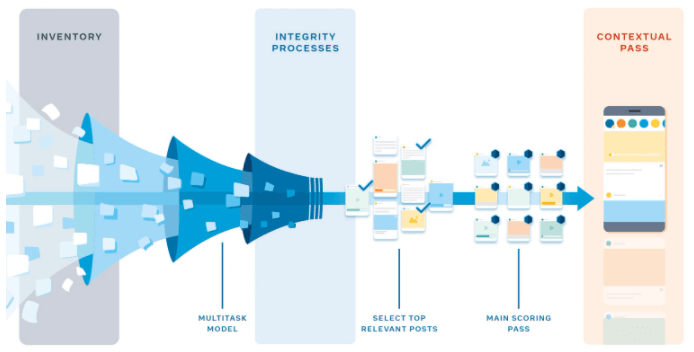
시스템 아키텍처에서는 피드 집계기(aggregator)를 쿼리하는 웹/PHP 계층을 사용합니다. 피드 집계기의 역할은 게시물에 대한 모든 관련 정보를 수집하고 모든 기능(이전에 이 게시물을 좋아했던 사람 수)을 분석하여 사용자에게 게시물의 가치와 최종 순위 점수를 예측하는 것입니다.
다중 작업 신경망을 사용하여 각각의 게시물에 점수를 매깁니다. 포스트의 유형, 임베딩, 뷰어가 상호작용하는 경향이 있는 것을 포함하여 게시물의 가치를 예측하는 데 사용할 수 있는 많은 특징이 있습니다. 이를 1,000개 이상의 게시물에 대해 계산하기 위해 수십억 명의 사용자 각각에 대해 실시간으로 예측 변수라고 하는 여러 대의 시스템에서 모든 후보 스토리에 대해 이러한 모델을 실행합니다.
그 후에 많은 예측 중에서 단일 점수를 계산합니다. 이제 우리는 모든 예측을 가지고 있고, 우리는 그것들을 하나의 점수로 결합할 수 있습니다. 이렇게 하려면 계산 능력을 절약하고 콘텐츠 유형 다양성과 같은 규칙을 적용하기 위해 여러 개의 패스가 필요합니다. 첫째, 특정 무결성 프로세스가 모든 게시물에 적용됩니다. 그런 다음 패스를 통과하면 경량 모델을 실행하여 A에게 가장 적합한 500개의 게시물을 선정합니다. 이것은 우리가 더 강력한 신경망 모델을 사용할 수 있도록 나중에 높은 회상율(recall)로 더 적은 게시물들의 순위를 매길 수 있도록 도와줍니다. 각 게시물을 독립적으로 채점한 후 500개 이하의 모든 자격이 있는 게시물을 점수별로 정렬합니다. 마지막으로 뉴스 피드를 다양화하기 위해 컨텐츠 유형 다양성 규칙과 같은 상황별 기능이 추가됩니다.
'Tech' 카테고리의 다른 글
| 인공지능 언어 모델 GPT-3의 간단한 이해와 원리 (1) | 2021.02.10 |
|---|---|
| 카프카(Kafka)의 간단한 개념과 원리 (0) | 2021.02.10 |
| 실제 산업에 빅데이터 기술을 적용하는 방법과 사례 (0) | 2021.02.08 |
| 차세대 디스플레이, 마이크로 LED 기술의 원리와 장단점 (0) | 2021.02.01 |
| 페이스북이 대규모 하드웨어와 시스템 장애를 처리하는 방법들 (0) | 2021.01.31 |




댓글